
Free Python script for Google Ads n-grams
N-grams can be a significant weapon for analyzing search queries on Google Ads or SEO. So, we’ve produced a free python script to help you analyze n-grams of any length across both your product feed and your search queries. We’ll explain what n-grams are, and how to use n-grams to optimize your Google Ads, particularly for Google Shopping. We’ll finally show you how to use our free n-grams script to improve your Google Ads results.
What are n-grams?
N-grams are phrases of N number of words, pulled out from longer bodies of text. The ‘N’ here can be replaced by any number.
For example, in a sentence like “the cat jumped on the mat”, “cat jumped” or “the mat” would both be 2-grams (or ‘bi-grams’).
“The cat jumped” or “cat jumped on” are both examples of 3-grams (or ‘tri-grams’) from this sentence.
How n-grams help search queries
N-grams are useful in analyzing search queries within Google Ads because certain key phrases can appear in many different search queries.
N-grams let us analyze the impact of these phrases across your whole inventory. They, therefore, let you make better decisions and optimizations at scale.
It even allows us to understand the impact of single words. For example, if you saw a weak performance by searches containing the word “free” (a ‘1-gram’), you might decide to negative that word out from all campaigns.
Or, strong performance through search queries containing “personalized” might encourage you to build a dedicated campaign.
N-grams are particularly useful for looking at search queries from Google Shopping.
The automated nature of Product Listing Ads keyword targeting means that you can surface for hundreds of thousands of search queries. Particularly when you have a large number of product variants with very specific features.
Our N-grams script lets you cut through that clutter to the phrases that matter.
Analyzing Search Queries with n-grams
The first use case for n-grams is analyzing search queries.
Our n-grams python script for Google Ads contains full instructions on how to run it, but
we’ll go over how to get the most out of it.
- You will need to have python installed on your machine to begin. If you don’t, it’s very easy. You first install Anaconda. Then, open up Anaconda Prompt and type ‘conda install jupyter lab’. Jupyter Lab is the environment in which you will run this script.
Simply download a search query report from your Google Ads. We’d recommend setting it up as a custom report in the ‘reports’ section of Google Ads. You can even set this up at the MCC level if you wish to run this script across multiple accounts.

3. Then, just update the settings in the script to do what you want, and run all the cells.
It will take a little time to run, but stay patient. You will see progress being updated on the bottom as it does its magic.
The output will appear as an excel file within whatever folder you are running the script in we would suggest using the downloads folder. The file will be labeled with any name that you define.
Each tab of the excel file contains a different n-gram analysis. For example, here is a bi-gram analysis:
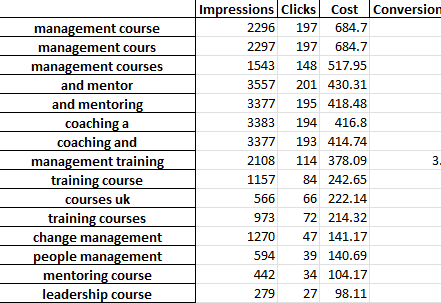
There are a number of ways you can use this report to find improvements.
You could start with the highest spending phrases and look at any outliers for CPA or ROAS.
Filtering your reports to non-convertors will also highlight areas of poor spending.
If you see poor converters in the single words tab, you can easily check what context the words are being used in in the 3-Gram tab.
For example, in a professional training account, we might spot that ‘Oxford’ performs consistently poorly. The 3-Gram tab quickly reveals that users are likely to be looking for a more formal, university-oriented course.
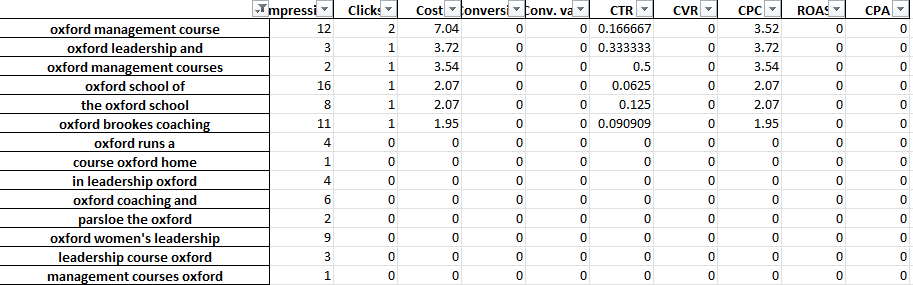
You can therefore quickly negative this word out.
Ultimately, use this report however it works best for you.
Optimizing product feeds with n-grams
Our second n-grams script for Google Ads analyses your product performance.
Again, you can find full instructions within the script itself
This script looks at the performance of phrases within your product titles. The product title, after all, determines to a large extent what keywords you show up for. The title is also your primary ad copy. Titles are therefore incredibly important.
The script is designed to help you find potential phrases within these titles which you can adapt to improve your performance from Google Shopping.
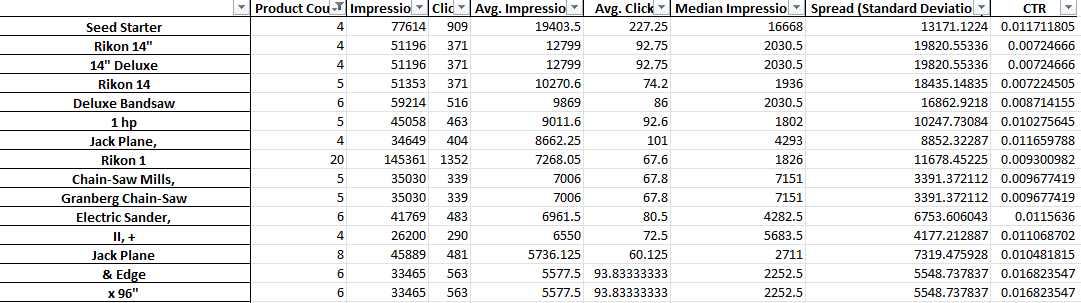
As you can see above, the output of this script is a little different. Because of limitations with Google’s reporting API, you cannot access conversion metrics (like revenue) whilst you are at the product title level.
This report, therefore, gives you product counts, average traffic, and the spread (standard deviation) of the product phrases.
Because it is based on visibility, you can use the report to identify phrases likely to make your products more visible. You can then add these to more of your product titles.

For example, we might find a phrase with a very high number of average impressions and which appears within the title of several products. It also has a low standard deviation – meaning that there isn’t likely to be just one amazing product that’s skewing our figures here.
We used this tool to dramatically expand shopping visibility for a client. The client sold products in thousands of different sizes. For example 8x10mm. People were also shopping for very specific sizes that they needed.
But, Google was bad at understanding the different possible naming conventions for this sizing: Searches like 8mm by 10mm, 8 x 10mm, 8mm x 10mm were all being treated as almost entirely different search queries.
We, therefore, used our n-grams script to determine which of these naming conventions gave our products the best visibility.
We found the best match and made the changes to our product feed. As a result, the traffic to the client’s shopping campaigns shot up by over 550% over the course of a single month.
Product naming matters and n-grams can help you with that.
N-gram scripts for Google Ads
Here are both of the complete scripts.
N-grams script for Google Ads search queries
#!/usr/bin/env python
#coding: utf-8
# Ayima N-Grams Script for Google Ads
#Takes in SQR data and outputs data split into phrases of N length
#Script produced by Ayima Limited (www.ayima.com)
#© 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/).
#Version 1.1
### Instructions
#Download an SQR from within the reports section of Google ads.
#The report must contain the following metrics:
#+ Search term
#+ Campaign
#+ Campaign state
#+ Currency code
#+ Impressions
#+ Clicks
#+ Cost
#+ Conversions
#+ Conv. value
#Then, complete the setting section as instructed and run the whole script
#The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly.
### Settings
# First, enter the name of the file to run this script on
# By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease.
file_name = "N-Grams input - SQR (2).csv"
grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results.
campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (e.g. "DSA,PLA"). Case Insensitive
campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (e.g. "DSA,PLA"). Case Insensitive
character_limit = 3 #minimum number of characters in an ngram e.g. to filter out "a" or "i". Will filter everything below this limit
client_name = "SAMPLE CLIENT" #Client name, to label on the final file
enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns
impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing
brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""]
"BRAND_TERM_2"] #e.g. ["Adidas","Addidas"]
## The Script
#### You should not need to make changes below here
import pandas as pd
from nltk import ngrams
import numpy as np
import time
import re
def read_file(file_name):
#find the file format and import
if file_name.strip().split('.')[-1] == "xlsx":
return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",")
elif file_name.strip().split('.')[-1] == "csv":
return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")
df = read_file(file_name)
def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include):
to_ex = to_ex.split(",")
to_inc = to_inc.split(",")
if to_inc != ['']:
to_inc = [word.lower() for word in to_inc]
df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))]
if to_ex != ['']:
to_ex = [word.lower() for word in to_ex]
df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))]
if enabled_campaigns_only:
try:
df = df[df["Campaign state"].str.contains("Enabled")]
except KeyError:
print("Couldn't find 'Campaign state' column")
return df
def generate_ngrams(list_of_terms, n):
"""
Turns a list of search terms into a set of unique n-grams that appear within
"""
# Clean the terms up first and remove special characters/commas etc.
#clean_terms = []
#for st in list_of_terms:
#st = st.strip()
#clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st))
#split into grams
unique_ngrams = set()
for term in list_of_terms:
grams = ngrams(term.split(" "), n)
[unique_ngrams.add(gram) for gram in grams]
all_grams = set([' '.join(tups) for tups in unique_ngrams])
if character_limit > 0:
n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit]
return n_grams_list
def _collect_stats(term):
#Slice the dataframe to the terms at hand
sliced_df = df[df["Search term"].str.match(fr'.{re.escape(term)}.')]
#add our metrics
raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]]))
return raw_data
def _generate_metrics(df):
#generate metrics
try:
df["CTR"] = df["Clicks"]/df[f"Impressions"]
df["CVR"] = df["Conversions"]/df["Clicks"]
df["CPC"] = df["Cost"]/df["Clicks"]
df["ROAS"] = df[f"Conv. value"]/df["Cost"]
df["CPA"] = df["Cost"]/df["Conversions"]
except KeyError:
print("Couldn't find a column")
#replace infinites with NaN and replace with 0
df.replace([np.inf, -np.inf], np.nan, inplace=True)
df.fillna(0, inplace= True) df.round(2)
return df
def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0):
"""Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """
#set up metrics lists to drop values
array = []
raw_data = map(_collect_stats, ngrams_list)
#stack into an array data = np.array(list(raw_data))
#turn the above into a dataframe
columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"]
ngrams_df = pd.DataFrame(columns= columns,
data=data,
index = list(ngrams_list),
dtype = float) ngrams_
df.sort_values(by = "Cost", ascending = False, inplace = True)
#calculate additional metrics and return
return _generate_metrics(ngrams_df)
def group_by_sqs(df):
df = df.groupby("Search term", as_index = False).sum()
return df
df = group_by_sqs(df)
def find_brand_terms(df, brand_terms = brand_terms):
brand_terms = [str.lower(term) for term in brand_terms]
st_brand_bool = []
for i, row in df.iterrows():
term = row["Search term"]
#runs through the term and if any of our brand strings appear, labels the column brand
if any([brand_term in term for brand_term in brand_terms]):
st_brand_bool.append("Brand")
else:
st_brand_bool.append("Generic")
return st_brand_bool
df["Brand label"] = find_brand_terms(df)
#This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches
i = 1
while len(df)> 40000:
print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}")
df = df[df[impressions_column_name] > i]
i+=1
writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter')
df.to_excel(writer, sheet_name='Raw Searches')
for n in grams_to_run:
print("Working on ",n, "-grams")
n_grams = generate_ngrams(df["Search term"], n)
print(f"Found {len(n_grams)} n_grams, building stats (may take some time)")
n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit)
print("Adding to file")
n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',)
writer.close()N-grams script for analysing product feeds
#!/usr/bin/env python
#coding: utf-8
# N-Grams for Google Shopping
#This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you
#Script produced by Ayima Limited (www.ayima.com)
#© 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/).
#Version 1.1
## Instructions
#Download an SQR from within the reports section of Google ads.
#The report must contain the following metrics:
#+ Item ID
#+ Product title
#+ Impressions
#+ Clicks
#Then, complete the setting section as instructed and run the whole script
#The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly.
## Settings
#First, enter the name of the file to run this script on
#By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease.
file_name = "Product report for N-Grams (1).csv"
grams_to_run = [1,2,3] #The number of words in a phrase to run this for (e.g. 3 = three-word phrases only)
character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols
title_column_name = "Product Title" #Name of our product title column
desc_column_name = "" #Name of our product description column, if we have one
file_label = "Sample Client Name" #The label you want to add to the output file (e.g. the client name, or the run date)
impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing
client_name = "SAMPLE"
## The Script
#### You should not need to make changes below here
#First import all of the relevant modules/packages
import pandas as pd
from nltk import ngrams
import numpy as np
import time
import re
#import our data file
def read_file(file_name):
#find the file format and import
if file_name.strip().split('.')[-1] == "xlsx":
return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",")
elif file_name.strip().split('.')[-1] == "csv":
return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")#
df = read_file(file_name)
df.head()
def generate_ngrams(list_of_terms, n):
"""
Turns our list of product titles into a set of unique n-grams that appear within
"""
unique_ngrams = set()
for term in list_of_terms:
grams = ngrams(term.split(" "), n)
[unique_ngrams.add(gram) for gram in grams if ' ' not in gram]
ngrams_list = set([' '.join(tups) for tups in unique_ngrams])
return ngrams_list
def _collect_stats(term):
#Slice the dataframe to the terms at hand
sliced_df = df[df[title_column_name].str.match(fr'.{re.escape(term)}.')]
#add our metrics
raw_data = [len(sliced_df), #number of products
np.sum(sliced_df[impressions_column_name]), #total impressions
np.sum(sliced_df["Clicks"]), #total clicks
np.mean(sliced_df[impressions_column_name]), #average number of impressions
np.mean(sliced_df["Clicks"]), #average number of clicks
np.median(sliced_df[impressions_column_name]), #median impressions
np.std(sliced_df[impressions_column_name])] #standard deviation
return raw_data
def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''):
"""
Takes in n-grams and df and returns df of those metrics
df - our dataframe
title_column_name - str. Name of the column containing product titles
ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols
desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe
"""
#first cut it to only grams longer than our minimum
if character_limit > 0:
ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit]
raw_data = map(_collect_stats, ngrams_list)
#stack into an array
data = np.array(list(raw_data))
#data[np.isnan(data)] = 0
columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"]
#turn the above into a dataframe
ngrams_df = pd.DataFrame(columns= columns,
data=data,
index = list(ngrams_list))
#clean the dataframe and add other key metrics
ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"]
ngrams_df.fillna(0, inplace=True) ngrams_df.round(2)
ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int)
ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True)
return ngrams_df
writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter')
start_time = time.time()
for n in grams_to_run:
print("Working on ",n, "-grams")
n_grams = generate_ngrams(df["Product Title"], n)
print(f"Found {len(n_grams)} n_grams, building stats (may take some time)")
n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit)
print("Adding to file")
n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',)
time_taken = time.time() - start_time
print("Took "+str(time_taken) + " Seconds")
writer.close()You can also find updated versions of the n-grams script on github to download.
These scripts are licensed under the Creative Commons BY SA 4.0 license, meaning that you are free to share and adapt them, but we would encourage you to always share your improved versions freely for everyone to use. N-grams are too useful not to share.
Want to learn more about how we can help your Paid Media or SEO efforts grow? Get in touch with us today.

